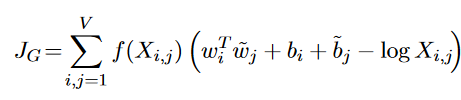Screenshot (10.10.2025) Google Search: human made content - Images
Auf einigen Internetseite habe ich jetzt öfters Badges (Abzeichen, Schilder) gesehen mit Texten wie: „Not By AI“, „Human Made Content“, „100% human made – NO AI USED“ und musste sofort an Walter Benjamins Text ‚Das Kunstwerk im Zeitalter seiner technischen Reproduzierbarkeit‘ denken 🤩🤗:
Der Mensch ist nicht so „wichtig“, wie er denkt (Anthropozentrismus, Religion, Bescheidenheit)
Werteverlust und Sinnkrise
Abseits von Sinnkrisen auf menschlicher Seite gibt es noch die real-existierende Krise der Daten-Trockenheit an von Menschen produziertem Content im Internet (human data drought) für KIs 😱😉… wie hier (einem von Synesis One (Scammy Micro-Task-Platform!) generierten/geschriebenen Text? ):
Gemini (2.5 Flash): Image: a person chatting with an ai and getting into a delusional spiral, animated
Die New-York-Times-Reporterin Kashmir Hill (Der Mensch & KI = Speichelleckerei & Suizid?!) berichtet auch im The Verge Decoder-Podcast über gruselige Beziehungen zwischen KI-Chatbots und Nutzenden.
Gemini (2.5): create an image with a happy thinking (about food) human being animated
„Soll ich heute Nudeln oder Reis kochen, wie antworte ich meinem Freund auf WhatsApp, lohnt sich der Weg in die Stadt oder bleibe ich besser zuhause – immer öfter lassen wir solche Fragen nicht mehr unser eigenes Gehirn entscheiden, sondern ChatGPT. Laut einer aktuellen Umfrage nutzen schon drei Viertel der Befragten KI im privaten Alltag. Für Keno ist das Grund genug, genauer hinzusehen: Was passiert, wenn wir immer mehr Denken an Maschinen auslagern, und welche Rolle spielen dabei Konzerne wie OpenAI, xAI oder Meta? Genau darum geht es im nächsten Video.“
c’t 3003 Hype <3003@newsletter.ct.de (26.08.2025)
Den c’t 3003 Newsletter habe ich abonniert, nachdem ich feststellen musste, dass es keine Podcast-Folgen von c’t 3003 (ok, eine Podcast-Folge gibt es…😊) gibt und ich das Video hören musste… 😉
„Binaurales Hörspiel, für Kopfhörer optimiert. Inspiriert vom Pionier der Elektromusik Karlheinz Stockhausen nutzen wittmann/zeitblom die technischen Möglichkeiten des Jahres 2020 für ein Hörspiel über die totale Kontrolle durch eine künstliche Superintelligenz.“
Let’s look at some other associations Word2vec can produce.
Instead of the pluses, minus and equals signs, we’ll give you the results in the notation of logical analogies, where : means “is to” and :: means “as”; e.g. “Rome is to Italy as Beijing is to China” = Rome:Italy::Beijing:China. In the last spot, rather than supplying the “answer”, we’ll give you the list of words that a Word2vec model proposes, when given the first three elements:
king:queen::man:[woman, Attempted abduction, teenager, girl]
//Weird, but you can kind of see it (skymind.ai)
Stichworte des Projektes sind: the coded gaze, algorithmic bias, unfairness, exclusion
Ziel des Projektes ist, den Einzug von Stereotypen und Vorurteilen (Sexismus und Rassismus) in KIs zu vermeiden.
Die Gründerin des Projektes Joy Buolamwini stellt das Projekt und die Hintergründe, die dazu führten, in einem ca. 9-minütigem TED-Video vor (deutsche Untertitel sind zuschaltbar):
Die mathematischen Deutungsräume (und damit auch Stereotype (language bias)), die durch Vektoren beim Word-Embedding in der KI entstehen, entsprechen dem, was auf menschlicher Seite im Zusammenhang mit Sprache Deutungsrahmen (Framing) genannt wird.
„PS: In jetziger Zeit kommt hinzu, dass wir unsere sprachliche Unkorrektheit an künstliche Intelligenzen weitergeben! Siehe z.B. auf Englisch, sciencemag.org: Even artificial intelligence can acquire biases against race and gender“ (inklusiv korrekt positiv: bewusst kommunizieren, Kapitel Signalwörter: das generische Maskulinum)
Im eBook hat es nur für eine Fußnote gereicht. Jetzt hatte ich Zeit, mich mit diesem spannenden Thema zu beschäftigen.
Natural Language Processing (NLP)
Wie macht eine KI Sinn aus unserer Sprache?
Indem sie durch Machine Learning große Datensätze an Text (corpus) menschlicher Sprache (natural language) verarbeitet und in mathematische Modelle (vector spaces) umwandelt.
Wiederholung (co-occurence) und Kontext (word embedding) sind dabei entscheidende Kriterien, um Wörter miteinander in Verbindung zu bringen (semantic connections, associations).
Auf diese Weise nähert sich eine KI der Bedeutung eines Wortes.
Dieser Prozess wird als Natural Language Processing bezeichnet (NLP)
Die enormen Datenmengen an verarbeitetem Text reproduzieren dabei in der KI die Stereotype, die bereits in unserer Sprache vorhanden sind.
Z.B. das englische geschlechtsneutrale Wort ‚programmer‘. ‚Programmer‘ tritt sehr oft im gleichen Kontext mit ‚he‘ und ‚computer‘ auf. Wohingegen z.B. ’nurse‘ mit ’she‘ und ‚costume‘ in Verbindung steht.
Oder: Europäisch-Amerikanische Namen finden sich in einem ‚positiven‘ Deutungsraum der KI wieder (happy, gift). Wohingegen afrikanisch-amerikanische Namen in einem ’negativen‘ liegen.
„“If you didn’t believe that there was racism associated with people’s names, this shows it’s there,” said Bryson“ in einem Interview (guardian.co.uk)
Die KI korrigiert ihre Vektoren und wird en-stereotypisiert (debiased).
Das sieht dann so aus:
Screenshot aus Learning Gender-Neutral Word Embeddings, Seite 2)
<ironie>Tja, Data-Wissenschaftler und Wissenschaftlerinnen haben es einfach .-) </ironie>
Ich denke, für humane Intelligenzen, die deutsch sprechen, lässt sich ein Teil des kryptischen Screenshots sehr schnell übersetzen: vermeide das generische Maskulinum.
Mein Fazit
Die oben genannte Studie bezieht sich auf die englische Sprache.
„…but things get more gendered [in languages] such as German…“ Aylin Caliskan (popsci.com)
Sprache ist nicht neutral und war es nie. Die Studie über Sprache und KIs zeigt, dass ein Zusammenhang zwischen Sprache und menschlicher Wahrnehmung (Kognition) und menschlichem Denken (z.B. Stereotype) besteht.
„How does bias get into language, do people start making biased associations from the way they are exposed to language? Knowing that will also help us find answers to maybe a less biased future.” Aylin Caliskan (popsci.com)
Der Süddeutschen Zeitung lag ein buntes Beiblatt bei: eine Anzeigensonderveröffentlichung von Google. Der Titel: Aufbruch – Künstliche Intelligenz – Was sie bedeutet und wie sie unser Leben verändert (06.10.18).
Zu den Fragen „Wie machen wir KI gerecht?“ und „Können Algorithmen Vorurteile haben?“ (S. 30) antwortet Fernanda Viégas, Leiterin der Goolge-Initiative PAIR (People+ AI Research):
„Digitale Voreingenommenheit entsteht üblicherweise durch Tendenzen im Datensatz, mit dem das Machine-Learning-System trainiert wird. Gibt es eine Unausgewogenheit in den Daten, wird sie sich auch in den Ergebnissen des Systems zeigen. Wenn etwa ein Datensatz mit Aussprachebeispielen auf männlichen Rednern basiert, wird ein Spracherkennungssystem, das auf diesen Daten basiert, sehr wahrscheinlich bei Männern besser funktionieren als bei Frauen. Ein solches System bezeichnen wir als voreingenommen zugunsten von Männern.“
Das hört sich gut an. Wir müssen uns mal wieder mit unserer Sprache auseinandersetzen. Diesmal in der Form von Datensätzen in menschlicher Sprache.
Wenn ich dann jedoch auf Seite 34 der Werbung für KIs von Google lese:
„Den Gedanken, dass Programmierer sich ihrer sozialen Verantwortung bewusst werden müssen, finde ich extrem bedeutsam.“ (Peter Dabrock)
dann wird mir angst und bange. Nicht nur wegen der fehlenden Ethik-Kompetenz aufseiten der Programmierenden, sondern wegen des generischen Maskulinums des Ethik-Professors.
Wie ethisch sind Visionen formuliert im generischen Maskulinum? Welche ethische Kompetenz kommuniziert der Vorsitzende des Deutschen Ethikrats damit? Wie ethisch ist seine Ethik?