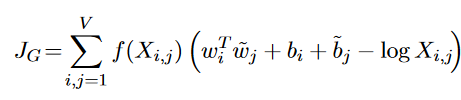Der Überwachungskapitalismus hat mich an den Plattformkapitalismus erinnert. Laut Wikipedia von Sascha Lobo 2014 als Deutungsrahmen (frame) in Umlauf gebracht.
Schön, dass auf wikipedia direkt der Artikel verlinkt ist, in dem Sascha Lobo den Samen für eine andere Sichtweise (Deutungsrahmen) der Sillicon-Valley-Realitäten in meinem Kopf gesäht hat.
„Was man Sharing-Ökonomie nennt, ist nur ein Aspekt einer viel größeren Entwicklung, einer neuen Form des digitalen Kapitalismus: Plattform-Kapitalismus.“ (Sascha Lobo, spiegelonline.de)
Die mathematischen Deutungsräume (und damit auch Stereotype (language bias)), die durch Vektoren beim Word-Embedding in der KI entstehen, entsprechen dem, was auf menschlicher Seite im Zusammenhang mit Sprache Deutungsrahmen (Framing) genannt wird.
„PS: In jetziger Zeit kommt hinzu, dass wir unsere sprachliche Unkorrektheit an künstliche Intelligenzen weitergeben! Siehe z.B. auf Englisch, sciencemag.org: Even artificial intelligence can acquire biases against race and gender“ (inklusiv korrekt positiv: bewusst kommunizieren, Kapitel Signalwörter: das generische Maskulinum)
Im eBook hat es nur für eine Fußnote gereicht. Jetzt hatte ich Zeit, mich mit diesem spannenden Thema zu beschäftigen.
Natural Language Processing (NLP)
Wie macht eine KI Sinn aus unserer Sprache?
Indem sie durch Machine Learning große Datensätze an Text (corpus) menschlicher Sprache (natural language) verarbeitet und in mathematische Modelle (vector spaces) umwandelt.
Wiederholung (co-occurence) und Kontext (word embedding) sind dabei entscheidende Kriterien, um Wörter miteinander in Verbindung zu bringen (semantic connections, associations).
Auf diese Weise nähert sich eine KI der Bedeutung eines Wortes.
Dieser Prozess wird als Natural Language Processing bezeichnet (NLP)
Die enormen Datenmengen an verarbeitetem Text reproduzieren dabei in der KI die Stereotype, die bereits in unserer Sprache vorhanden sind.
Z.B. das englische geschlechtsneutrale Wort ‚programmer‘. ‚Programmer‘ tritt sehr oft im gleichen Kontext mit ‚he‘ und ‚computer‘ auf. Wohingegen z.B. ’nurse‘ mit ’she‘ und ‚costume‘ in Verbindung steht.
Oder: Europäisch-Amerikanische Namen finden sich in einem ‚positiven‘ Deutungsraum der KI wieder (happy, gift). Wohingegen afrikanisch-amerikanische Namen in einem ’negativen‘ liegen.
„“If you didn’t believe that there was racism associated with people’s names, this shows it’s there,” said Bryson“ in einem Interview (guardian.co.uk)
Die KI korrigiert ihre Vektoren und wird en-stereotypisiert (debiased).
Das sieht dann so aus:
Screenshot aus Learning Gender-Neutral Word Embeddings, Seite 2)
<ironie>Tja, Data-Wissenschaftler und Wissenschaftlerinnen haben es einfach .-) </ironie>
Ich denke, für humane Intelligenzen, die deutsch sprechen, lässt sich ein Teil des kryptischen Screenshots sehr schnell übersetzen: vermeide das generische Maskulinum.
Mein Fazit
Die oben genannte Studie bezieht sich auf die englische Sprache.
„…but things get more gendered [in languages] such as German…“ Aylin Caliskan (popsci.com)
Sprache ist nicht neutral und war es nie. Die Studie über Sprache und KIs zeigt, dass ein Zusammenhang zwischen Sprache und menschlicher Wahrnehmung (Kognition) und menschlichem Denken (z.B. Stereotype) besteht.
„How does bias get into language, do people start making biased associations from the way they are exposed to language? Knowing that will also help us find answers to maybe a less biased future.” Aylin Caliskan (popsci.com)